共用試験CBTにおけるIRT利用の実態の考察と、共用試験CBT学習法のレビュー、および提案
アローラ、MDMAと申します。
前回の記事では思いっきりよくわからん方向にイキってしまったのですが、今日CBTの結果も返ってきたことですし、今回は反省会みたいな、普通に真剣なノリでいきます。

キモいタイトルにしてしまい、すみません。
また、28,000字もあるので、何をどこに書いたのかが私の頭の中で処理しきれず、修正するにも長すぎて面倒という理由で、文章のつながりが悪いところがあるかもしれません。
0章がクソ長い上にちょっと難しくて正直読みづらいし、自己満で書いたようなものだしで、人を選ぶような内容になってるので、手っ取り早く結果とか勉強法とか見たい人は「0-(4).小括」から読むといいと思います。
0. CBTというテストについて 概要と理論的基礎
0-(1). 概要
パソコンをポチポチしてテストを受けるという意味(?)のCBT(Computer Based Testing)という言葉はなにも医学部の学生の間でだけ使われている言葉ではありません。例えばTOEFLなどでもこの言葉が使われているようです。精神心理医学方面の人にとってはCBTといったら認知行動療法のことです。
まあそんなことはさておいて、今私が話題に挙げている「共用試験CBT」は、「医学部4年生が受ける、医学部5年次以降の医療行為の違法性を阻却するための資格認定試験」*1 のことです。
※医師以外の自然人が他人に医療行為をすることは「刑法」における傷害罪になってしまいます。ただし、医学部5年生以上の高学年は、医師ではないのですが、CBTに合格することによって"Student Doctor"という身分となり、医療行為の違法性が阻却されます。
要は自動車教習所でいうところの仮免筆記試験みたいなものです。当然、5年生への最も重要な進級要件として位置づけられています。
自動車教習所の仮免筆記試験に例えたものの、突破難易度には天と地ほどの差があると言われています。*2 CBTの範囲はざっくり言うと「医学部の2〜4年生で習った事項すべて」なので、通常は医学部に通っている学生が数ヶ月準備して臨むものです。もしかしたら仮免筆記試験よりもセンター試験や公務員試験とイメージが近いかもしれませんね。
まあセンター試験や公務員試験といったスコア化される試験としての色が強くなってくると、当然現れるわけです。「マウント勢」が。*3まあ、私もなのですがね。こういう記事を書くからには逃れられない宿命みたいなものだと思います。
私も本心では「ソウイウノアンマヨクナイトオモウ…」(小声)ので、他人が読んでてできるだけ、少なくともマウント方面の苛立ちを覚えることの少ないように配慮したいと思っている所存です。タイトルで即オチでしょうか。すみません(マジで)。本文はと言うと、前半3/4くらいはCBTの理論的な説明しかありませんが、後半1/4くらいはたぶん多少なりのマウント行為があります。ご了承ください。
まとめると、CBTっていうのは「医学部の2〜4年生で習った事項すべてが試験範囲の、超ヤバいテスト!(マウント合戦もあるよ!)」となります。
0-(2). 項目反応理論(IRT)
マウント合戦にはよく「正答率○○%」というフレーズが用いられています。というか、多分ほとんどの受験生の目標設定も正答率をベースに考えられていると思います。まあわかりやすくていいですもんね。
まあ正答率という指標も良いんですけれども、ちょっと暇なのでもうひとつの指標である「IRT標準スコア」について、テストセンター配布資料やGoogle先生、図書館から取り寄せたIRTの入門書を携えて考察してみようかと思います。このあたり、ほかのCBTマウントブログと差別化を図っていきたいですね。(筆者注:いろいろな調整が難しく、終盤のほうは厳密性もクソもなくなってしまいました。残念。)
***
私などよりももっとちゃんとした人が解説してくれているもの↓
大分大学医学部の先生が、学生向けに公表しておられるIRTの解説PDFへのリンクです。
http://www.med.oita-u.ac.jp/mededuc/cbt/riron_about.pdf
http://www.med.oita-u.ac.jp/mededuc/cbt/riron_IRT.pdf
厚生労働省省医道審議会医師分科会による、共用試験の解説スライド(?)です。
https://www.mhlw.go.jp/content/10803000/000519143.pdf
***
0-(2)-i. IRTの目的
受験生界隈に古くから伝わるネタにこのようなものがあります。
一週間で偏差値40→偏差値70!その心は!?(東大実戦模試→進研模試)
受験生やってるとこういうことよくありますよね。すなわち、問題難易度や受験生集団の違いによって、返ってくる成績に大きな隔たりができてしまう件。まあこの事例においては、東大はちょっと難しいかもね~、でもほかの大学の選択肢は結構あるかもね~くらいの有意義な情報が得られているので、別に進研模試や東大実戦模試に文句をつける意図はありません。ただし、このように偏差値や得点率だけで個人の能力を測定しようとすると、問題難易度や受験者のレベルの不均一さ、さらには出題側の配点設定の恣意性によっていろいろな問題が生じてくる場面もあるということは想像に難くないと思います。
そこで、問題難易度や受験者集団にとらわれずに、「受験者本人の試験日当日の真の学力を数値として推定できないか!?」という無茶要請を叶える魔法の杖ない?、という話になります。その魔法の杖こそ、項目反応理論-IRT-です。もっとも、ファンタジーにおける本物の魔法の杖よろしく、誰でも簡単に使えるような代物ではなく使いこなすには相応の理解が必要となります。ちなみに私は表面だけ理解したつもりで記事を書いています。

「項目」という言葉は「テスト問題」という意味で、「項目反応」という言葉は「それぞれ個別の問題に対しての反応(マルバツ)」のことです。後述しますが、このようにそれぞれ問題特性が既に判明している設問に対する反応を直接測定することによって、たとえ受験者間で異なる問題が出題されたテストであっても、ひとつのものさしで受験者のレベルを推定することができるようになります。早い話、CBTは「出される問題は違うけど、公平になるようによく練られた試験」だということです。
0-(2)-ii. IRTの方法
0-(2)-ii-① IRTの方法概論
IRTで測定したい受験者の学力を能力値(θ)とし、これが標準正規分布(すみません、この程度の数理統計学の基礎については、大学の公衆衛生学の講義でも取り扱われるため、既知であるとします)に従うと仮定します。

※厳密には標準正規分布以外の分布を使うこともあるらしいのですが、共用試験CBTは学生の能力値(θ)の分布を標準正規分布と仮定しています。
IRTでは、出題された項目への解答状況(〇か×か)とその項目の難易度などのパラメタを用いて、受験者の能力値(θ)を推定することができます。
これだけ言われてもなんのことやらサッパリですよね。少し簡単な具体例を提示し、そのあとで理論的な話を始めましょう。大分大学のPDFおよび「新テスト」の学力測定方法を知るIRT入門(河合出版)、教育心理学会チュートリアル2018資料に記載されていた具体例です。
0-(2)-ii-② 視力検査の一例
視力検査を受けたことのない人はおそらくいないのではないでしょうか。学校検診でやりますしね*4。
視力検査は、いろんな難しいことをとっぱらったIRT式テストと考えることができます。
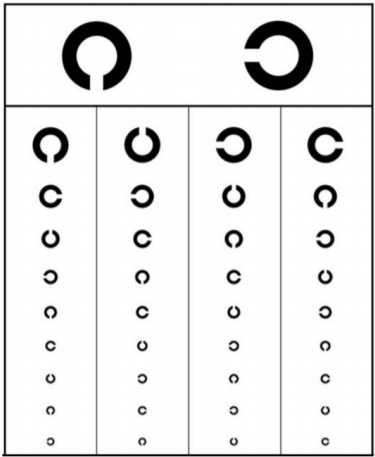
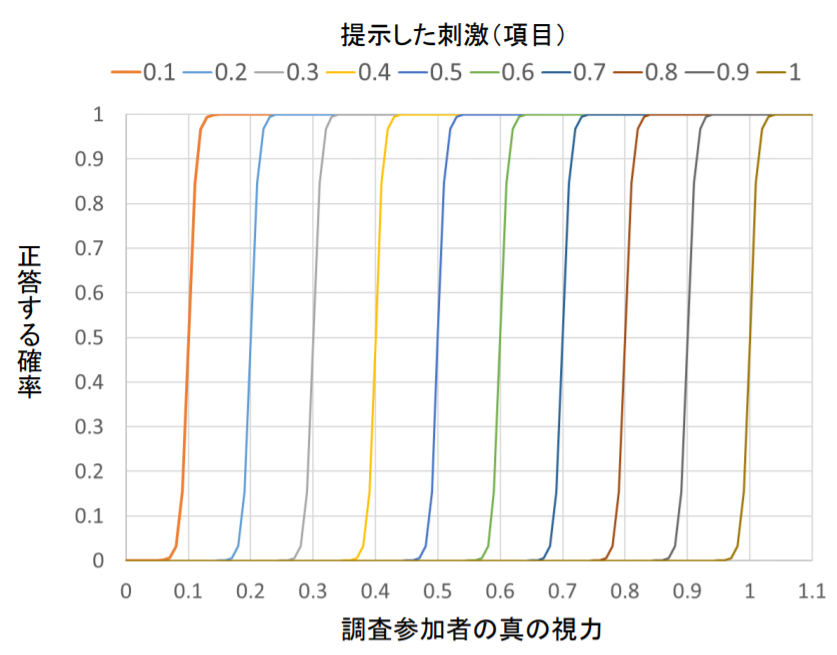
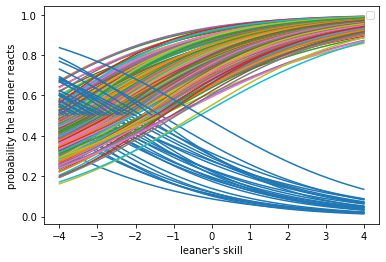
「項目反応」とは、「それぞれ個別の問題に対しての反応(マルバツ)」のことであり、IRT型テストとはその項目反応によって個人の能力値を推定し、スコアが決まるというものでした。視力検査における「項目」はそれぞれのランドルト環で、それぞれのランドルト環は大きさによって正答に至る難易度があらかじめ定められています。たとえば、被検者の真の視力ごとの、上から6番目のランドルト環の穴の向きを正しく答えられる確率は理論的には下図のようになります。

この曲線をヒントにすると、上から5番目までのランドルト環(視力0.5相当)の向きをすらすら答えていた人が6番目(視力0.6相当)のランドルト環で急に答えに詰まりだして、7番目(視力0.7相当)より下のランドルト環では全く見当違いの解答をする、あるいは「わかりません」と言い出した場合のその人の視力は、(真の視力は、その人の眼球を解剖して角膜、水晶体の屈折率や眼軸長を測定しないとわからないのにも関わらず)直感的な確率計算によって0.6であると推定されます。
もちろん視力0.6しか測定できないというわけではなく、視力検査では、下図のように、様々な難易度の項目が用意されています。これらの項目を先ほどの視力0.6の場合と同様に用いると、被検者の視力を0.1~1.0の10段階でかなり正確に推定することができます。一方で、この項目プールでは視力2.0や6.0とかの人、あるいは視力0.01や0.01すらない人の視力はまったく推定できないということも、興味深いですよね。
ところで、実際の視力検査では、答えに詰まりだすと上から下に向かってランドルト環の向きを聞かれていたのが急に両隣のランドルト環の向きを聞かれるようになりますよね。あれはちゃんと視力が0.6であることを確かめるために、すなわち、ちゃんと6番目のランドルト環の向きの正答率が0(ランドルト環の向きの場合は、全く見えなくても当て推量によって0.25の確率で正解できるから、ここは0.25とするのも手でしょう)でもなく1でもないことを確かめているのです。これは後述するCAT(コンピュータ適応型テスト)と仕組みが似ています。
また、視力検査のお姉さんは、被検者の回答状況から自分の頭の中で無意識に何らかの確率計算をして、被検者の視力がいくつであるのかを推定してカルテに記入しています。IRT型テストではこの確率計算をもっと厳密に理論化したものが用いられています。
この手の検査の良いところは、規格さえ守って設計されていれば、ランドルト環の向き(項目の具体的内容)が変わったとしても被検者の能力を同じ要領で測定できるということです。これにより、規格が同一であるならば、全国どこの眼科で誰が測定しても全く同じ条件で被検者の視力を得ることができます。
もしも視力検査がこのような形式ではなく、例えば正答率をものさしに用いていたら、「大きなランドルト環(簡単な項目)の正答率100%」な人のほうが「小さなランドルト環(難しい項目)の正答率50%」な人よりも視力が良いということになっちゃいます。(本当は、これだけの情報ではどっちの視力が良いかはわからない)これと同じような逆転現象は、制限時間の設定が厳しくなっちゃった系の定期試験などでも起こりそうですよね。ってか、入試でもふつうに起こりうると思います。(東大入試とかも、制限時間の間で簡単な問題を拾うだけで、難問だけにチャレンジした人よりも得点上は高い評価をもらえがちだし。個々人の受験の戦略を悪く言うつもりはありません。)
一方、ランドルト環の向きを暗記されたり(問題流出)、逆の眼でこっそりカンニングされたりすると、正確な視力を算出できません。また、項目プールの特性によっては、推定することが不可能な能力領域が存在します。以上の長所と短所は、IRT型テストにも概ね当てはまります。
0-(2)-ii-③ 項目プールと項目特性
IRTを採用したテストでは、視力検査と同じように、予め難易度などの特性がわかっている項目がたくさん用意されます。これが項目プール(プール問題)と呼ばれるものです。
例えば5項目から成る項目プールの各項目の難易度などのパラメタは下図のように表されます。これを項目特性曲線(ICC)と呼びます。
難易度(困難度)や識別力の異なる5項目の項目特性曲線 参考
qiita.com

上図の横軸は、項目回答者の能力値(θ)を表しています。共用試験CBTではθが標準正規分布に従うと仮定しているということは既に確認しているので、受験者のθの平均は0、標準偏差は1となります。θの絶対値が3を超える人はそうそういません。
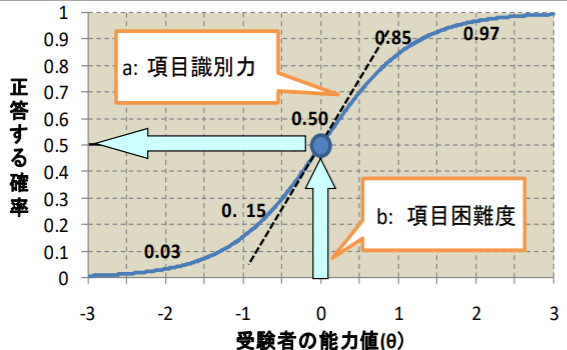
図中のbは、その項目に50%で正答することができる能力値(θ)を与えています。bが大きい項目の曲線は右方に、bが小さな項目の曲線は左方に位置することは明らかです。bは大きければ大きいほど正答するために高い能力値が必要となるため、「困難度」とも呼ばれています。
図中のaは、θ=bでの曲線の傾きです。困難度付近での項目特性曲線の傾きが大きいということは、困難度付近のθにおいて、その項目に正答するか誤答するかの確率が能力値(θ)によって大きく変わるということを意味します。すなわち、aが大きいほど回答者の能力を正しく推定することができる所謂”良問”となります。aは、θの大小の識別精度に関わるパラメタなので、「識別力」とも呼ばれています。
ここで、誰が、どのようにして困難度や識別力を決定しているのかという疑問が生じます。これを作問者が恣意的に設定しているのであれば、公平な試験とはなりえません。
この困難度や識別力といったパラメタは、予め試験実施前に、たくさんの受験者の解答の結果によってロジスティック回帰モデルによって推定されています。どのようにしてテスト実施前にこのような分析データを集めているのかというと、CBT本番に出題される「新問」やら「採点対象外」やら言われている問題がまさにそれです。ここで収集したデータから項目の困難度や識別力を推定し、さらに「等化」という線形変換のプロセスにより、既にある項目プールと全く同じものさしの上で受験者の能力値を推定できる次年度以降のプール問題を再生産しています。
つまり、来年度はじめてプールされる項目の困難度や識別力を与えているのは、今年度CBTを受験した我々ということになります。
0-(2)-ii-④ 最尤推定法による能力値(θ)の算出
さて、いよいよここから、θをどのように算出するかについての話に移ります。項目反応理論では、項目ごとに項目特性曲線(ICC)が求められていることは確認済です。したがって、ある項目に対して、θがわかればその項目に正答(誤答)する確率を求めることができます。数学的には、正答(誤答)確率がθの関数として表現されているともいいます。
ここで、ある項目に正答(誤答)したという情報が与えられると、「あ〜、θがもしこの値だったら、この結果になる確率はこのくらいだね〜」という見通しを立てることができます。例えば、ある人が困難度1の項目に正答したとき、もしθが1であればそのような結果になる確率は常に50%です。θが2であったら、詳しい項目特性曲線の形次第ですが、そのような結果になる確率は50%を超えた確率になっているはずです。本来はしませんが、θに無限大を仮定すると、確率は1になります。
複数の項目への正誤情報が与えられても、各項目への正答確率が確率論の独立の法則さえ満たしていれば*5、積の法則によって、観測された事象が生じる確率を計算することができます。このような積の計算によって算出されたn個の事象の同時確率のことを、「尤度」と呼びます。尤度はθの関数になっているので、解析によって尤度が最大となるθを求めることができます。それこそが「最尤推定法」であり、そのときのθこそが項目反応理論によって推定された能力値(θ)になります。
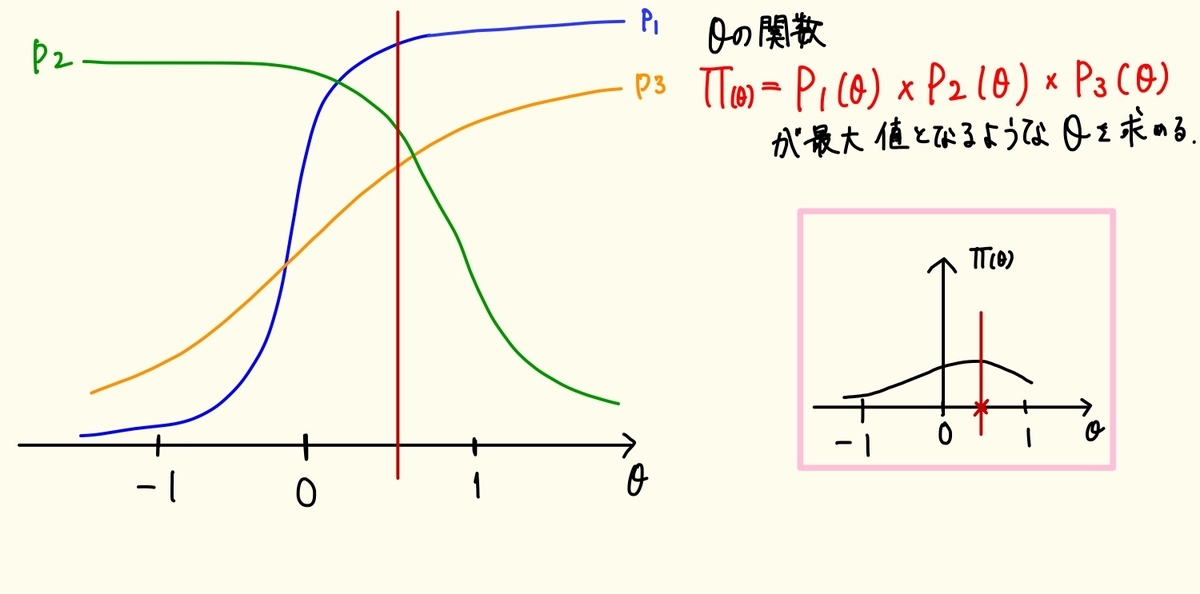
0-(2)-ii-⑤ 最尤推定法の具体例と考察
様々な条件で、0.1刻みのθで尤度関数の値を計算し、能力値θを推定しました。
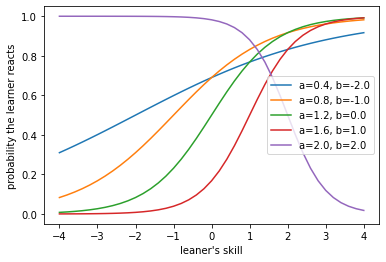
この場合、θ=1.7のときΠは最大となります。困難度1.6の項目まですべての項目に正答し、困難度2.0かつ識別力の高い項目には誤答しているため、受験者の能力値(θ)が1.7であるのは感覚とも一致しますし、図を見てもそのあたりでどの曲線もほどよく値が大きくなっていることがわかります。
この場合、θ=1.6のときΠは最大となります。テスト項目のサンプリングとしては、一つ上の項目セットよりも識別力の高い問題が選ばれていて、一見こちらのほうが受験者の能力値をよりよく推定しているといえそうです。しかし、たった5項目だけによって構成されているテストでは、識別力の高い項目があるとどうしても能力値(θ)がそちらに引き寄せられてしまうという傾向があるらしく、受験者としては正解した項目の困難度の条件は同一であるのに、一つ上のテスト受験時よりも見積もられるθが下がるという不本意な結果となってしまいました。本来、この受験生の能力値は1.5を超えるところにあると推定されるため、あまりにも易しい項目によってノイズがかかってしまうことは良くないと思うのは私だけでしょうか。

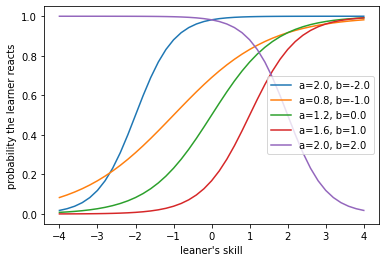
この場合、θ=1.9のときΠは最大となります。困難度1.6の項目に誤答していますが、困難度2.0で識別力も高い項目に正答しているため、受験者の能力値(θ)が1.9であるのは感覚とも一致するでしょう。
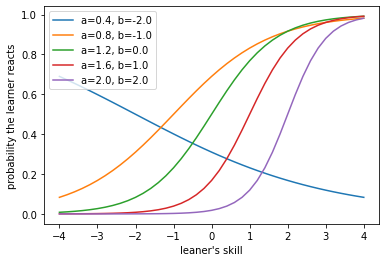
この場合、θ=3.0のときΠは最大となります。困難度-2.0の項目に誤答してはいますが、その項目の識別力がほかの項目に比較して低いことや、他の項目のすべてに正答していることによって能力値(θ)は高い値となりました。

この場合、θ=1.6のときΠは最大となりました。2つ目のテストでも見たように、識別力の高い項目の正誤は受験者の能力の見積もりに大きな影響を与えるため、困難度が低くて識別力が高い項目は、あるだけで能力値(θ)の見積もりを下げるだけでなく、誤答したときのダメージも甚大ではないということが示唆されています。つまり、誰でも正解できるような簡単な問題を取りこぼすと成績に響くということです。
なんとなく狐につままれたような説明に感じるかも知れませんが、これらの例から理論的・視覚的に最尤推定法のイメージをつかんでいただきたいところです。
最尤推定法の確率計算は、実施された項目の数が増えれば増えるほど複雑にはなりますが信頼性の高いものとなります。また、項目数が増えると、上の例で見られたような「一問の誤答によって能力値(θ)の見積もりが大きく変動する」といったことも起こりづらくなります。
共用試験CBTでは240項目を計算に用いています。

※いろいろな人の記事を読んで、そして私の結果でもって計算したみたら、五肢択一192項目、多選択肢28項目、連問形式28項目の合計248項目が採点対象になっているようでした。
248項目とした根拠記事
note.com
0-(3). 共用試験CBTではどうなっているか
ではここから、IRTが共用試験CBTにはどのように利用されているのかを見ていき、実際にネット上に転がってる成績表を用いて計算機で共用試験におけるIRTのモデルを実装してみた結果についてお話します。結論から申し上げますと、IRTモデル実装には失敗(?)し、面倒くさくなったので失敗したまま記事を書きました。また、248項目であることに気付く前に諸々の計算を済ませてしまったので、240項目で計算を回した結果を載せています。
◎共用試験CBTにはIRTがどのように活用されているか(ここは失敗してない)
コンピュータ実施である意味はあるのだろうか
そもそも、CBT型のテストは、IRTを用いたCAT(コンピュータ適応型テスト)という、受験者の学力レベルに応じて出題される項目の困難度が調整されるテスト様式が採られていることが一般的です。つまり、まずはじめに標準的な困難度の項目が提示され、それに対する反応を見て次に提示される項目の困難度が変わっていきます。そして、一定の困難度になったときに受験者の正答率がおよそ50%になったところで能力値(θ)を推定し、割と少数の項目でテスト終了となります。この場合、受験者ごとに出題される項目の困難度はまちまちとなります。上に挙げた視力検査の例みたいなものです。視力0.1もないような人に視力2.0用のちっさなランドルト環の向きをわざわざ聞かないでしょう。
しかし、共用試験CBTでは、受験生ごとに出題される項目の平均難易度が一定となるように調整されています。せっかくIRTによって項目難易度に関わらず受験者の能力を少数の項目で平等に、あるいは受験者ごとに集中して出題される困難度帯を調整し、きめ細やかに能力を推定できるというのに、わざわざそのようなIRTのうまみをひとつ捨て、「見かけの平等さ」が重視されていると考えられます。
このような条件では、受験者ごとに異なる項目が、簡単なものから難しいものまで平等に(※均等ではない)出題されます。そのような場合、テストの特性としては、幅広い能力帯で能力を推定できますが、領域によってはピンポイントでの精度に欠けるというものになります。(イメージとしては、縦にとても長い視力検査板があって、幅広い視力の人に項目を提示できるが、横移動ができない場所があり、ここぞのところで視力検査の精度を上げることができない場合がある。CAT方式では、受験者ごとに横移動できるポイントを調整できる。)
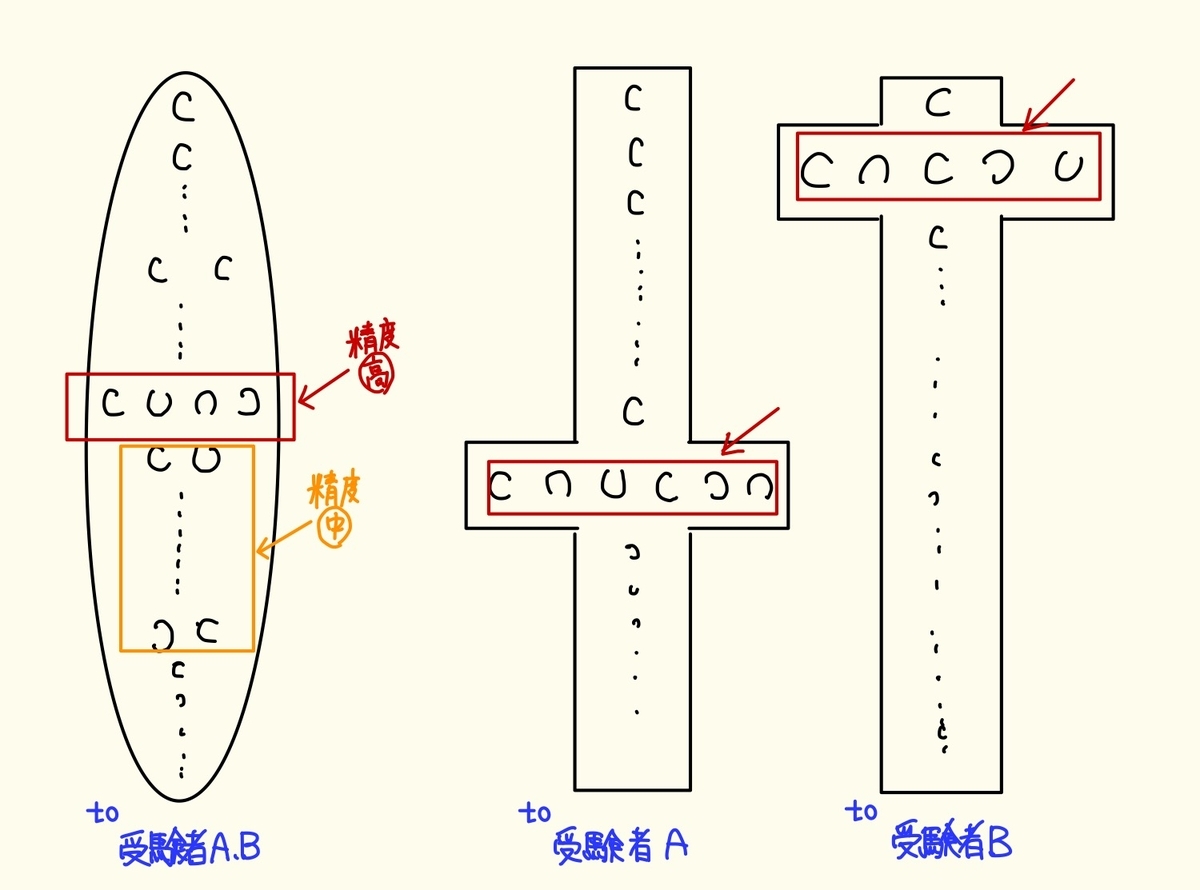
CBTはもともと基準に満たない学生の足切りのための試験なので、特にボーダーライン上での能力推定の精度は高めておきたいところです。もし対応するならば、他の困難度の出題に比べてボーダーライン上、つまり足切りレベルの困難度の項目をたくさん出題すれば、一応当初の目的を達成することはできます。
実際、下で述べていますが、共用試験CBTで出題される項目困難度の最頻値と平均値が-2.0付近であると推定することもできます(し、平均値が-2.0であるだけで、どの困難度の項目も均等に出題されている可能性もあります)。ここでは受験者の能力値に正規分布を仮定しているので、困難度が-2.0付近の項目を多く出題して下位5%を切り捨てる試験として、共用試験CBTは意外と機能しているようにも感じられます。一方で、項目困難度の分布に上のような分布を仮定すれば、ボーダーラインから離れたところに能力値を持つ受験生の能力推定には誤差が生じやすくなるということになります。
順次解答四連問はCBTに適した出題なのだろうか
最尤推定法では、独立の法則が満たされたときの同時確率を計算しています。では、独立の法則が満たされなかったとき(例えば、受験数学や物理の問題のように、前の小問の答えを間違えると雪崩を起こしてそれ以降の問題の答えも間違う方式:四連問はどうなるのかが問題となる。)はどうなるのでしょうか。
調べたところ、独立の法則を満たしていない項目が含まれていても無理やり計算できるらしいですが、あまり推奨されていないみたいです。
では共用試験CBTに出題される四連問はどうなっているのかについて見ていきましょう。結論から申し上げますと、四連問はそれぞれ「独立した」設問とすることができると考えられます。
共用試験に出題される四連問では、みなさんうんざりしているように、前の項目に戻れない代わりに、直前の項目の正誤を含めた、現在の項目を解くのに必要なすべての情報が受験者に与えられるからです。ここまでお膳立てされると、四連問という名に反し、4問のそれぞれ独立した項目として見ることができます。したがって、共用試験のセクション6は、計算上はおそらく何の配慮もされずに単純に28項目に対して解答したというように扱われると考えられます。
問題が流出したIRTという現状
共用試験CBTは、問題流出をご発度としていますが、みなさん御存知の通り、予備校業界は流出復元問題と称した問題集を販売しており、多くの医学生がそれを中心に据えて勉強するという現状があります。
これまで見てきたとおり、IRT型テストに用いられる項目プールには、わざわざ事前の試行、毎年の吟味を手間暇かけて受けてきて正答率が調整された良問が揃っています。そのような箱入り娘っこ問題たちのダイジなところを濫りに覗き見るようなことは果たして・・・。この事態が共用試験CBTの成立の根幹を揺るがすほどの大事件とまでは考えていませんが、少なくとも返却されたIRT標準スコアには、成績を上昇させる向きの系統的バイアスがかかっていると考えます。そのため、推定されるのが、「受験者の能力」というよりは、「共用試験CBTで得点できる能力」になっているのかもしれません。
私もそうやって勉強してきた身なので、この件についてなんらかの強い主張を行うことはできないのですが、ここまで「CBTは平等」というを謳ってきたところ、その実、平等な試験としては完璧ではないところもあるということは確かでしょう。
240項目に解答した場合のICCの具体的検討
ではここから、モデルの実装を試みた結果の段となります。項目数を248240に増やしてシミュレーションしてみた結果を御覧ください。(ここから割と失敗してます)
参考+データソース
note.com
※何度も申し上げますが、私の実力不足により、この節のここから先の部分の厳密性は保証できません。ご了承ください。
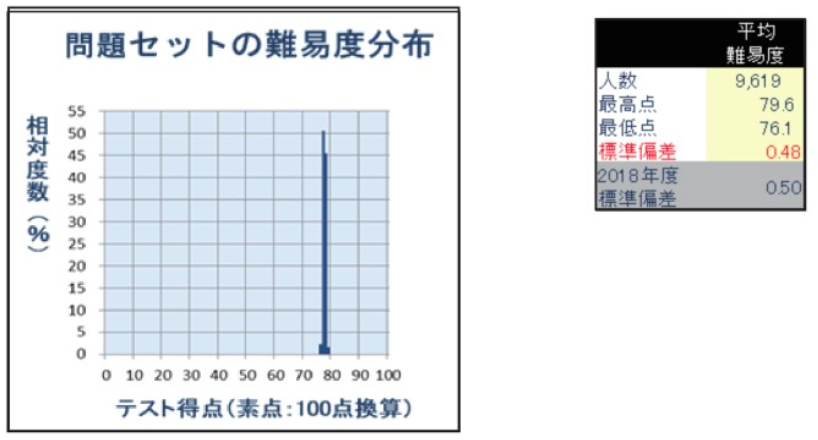
共用試験CBTでは、ICCの各パラメタは下表のように設定されているそうです。
厚生労働省資料(2019/6/19)より

識別力0.44という数値は、知っている人が見たら少し心もとない数値のように思われると思うのですが、下で実際にシミュレーションしてみた結果どうやら本当に識別力は0.44あたりらしいです。難しく言えば、ロジスティック関数を正規累積関数に近似するために定数D=1.7をかける手間は既に為されているらしいということです。
困難度は、500を平均とし、標準偏差を100としてあるようです。すなわち、困難度300というのは、能力値(θ)=-2の受験生が50%正答できるということになります。それに忠実にいくならば、共用試験CBTの項目の平均困難度はおよそ-2.0となります。しかしながら、そのような条件で計算を回してみると、どのサンプルでも成績表の数値+1くらいの能力値(θ)が返ってきてしまったんですよね。
そこで・・・
困難度の平均値を-3.0θとして計算しました。明らかな研究不正です。ごめんなさい。(ホントは、最初うっかり間違えて困難度平均-3.0で計算回してたらうまい結果が得られてぬか喜びしてたところ、後になって困難度平均が-2.0と気づいて萎えて、修正するのも面倒になった。)
Jupyter Notebook上で、識別力を平均0.44標準偏差0.05で240個、困難度を平均-3標準偏差1.0で240個、正規分布に従うように得て、240個の特性曲線の方程式をランダム生成し尤度関数を立式しました。(標準偏差とか与えられてないから適当に定めてるし、困難度1ズレてるしもういろいろとガバガバなんだよなあ)見た目だけは案外それっぽくできたので、高速スクロールして「そういう雰囲気」を楽しんでもらいながら見逃してもらえたら幸いです。


このとき計算されたIRT標準スコアは900でした。おそらく実際のテストでは800台前半くらいの数値が出ている成績なので、私のポンコツモデルは超上位者の成績の説明には向かないようです。もし困難度の平均を‐2θとしていたらIRT標準スコアが1000(900すらいないのに!)くらいになってしまいます。う~ん

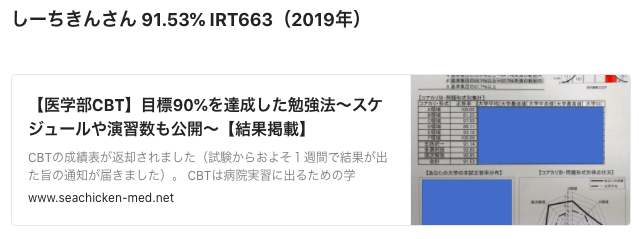

このとき計算されたIRT標準スコアは707でした。


得点率83.46%を仮定し、IRT標準スコアを計算すると、586となりました。まだ誤差が大きいです。
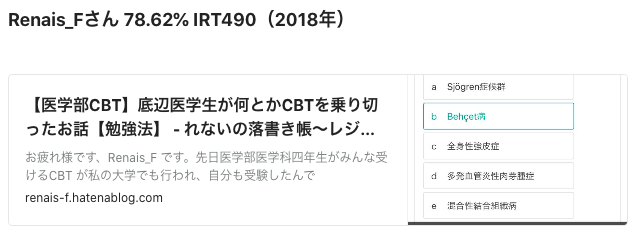

得点率78.6% を仮定し、IRT 標準スコアを計算すると、500となりました。急に誤差が無くなって不気味です。


得点率77.4% を仮定し、IRT 標準スコアを計算すると、487となりました。


得点率72.58% を仮定し、IRT 標準スコアを計算すると、447となりました。低いθに対してはなぜかそれっぽい結果を得ることができました。
う〜〜〜〜〜〜む。
まあ、研究不正はあるんですが、厚労省が出してた資料と、こんなグラフをいくつも見たら、次のことはなんとなく伝わるかなと思います。
・多くの人にとって、CBTの項目は比較的易しめのもの(100%は無理でも50%以上のそこそこの確率で当てられる項目)が多いと考えられる。
これが「怖がってたけど思ってたより点が取れた」の正体ではないのでしょうか。
また、計算を回してみた者の感想としては、私のポンコツモデルでも正答率90%を超えるあたりからIRT標準スコアが急に伸びたように感じます。ここまでくると一問の差で大きく差が開いてしまうのかもしれません。
0-(4). 小括
・CBTはひとりひとり出る問題が違うテストで、出題される問題の困難度は受験者の実力の高低によって決まり、より困難な課題をより多くこなした者の能力を高く推定するという体系である。
・↑これが本来のCBTにあるべき形であるが、共用試験CBTでは事情が異なり、受験者ごとに問題困難度が均質化されている。
・受験者の実力の推定には、事前施行によって算出された項目ごとのICCと最尤推定法を用いる。
・IRT標準スコアとは、出題された項目から推定された能力値が正規分布に従うと仮定したときの偏差値みたいなものと考えてよい。ただし、受験集団、受験時期ごとに変わってしまう、模試などでよく用いられている一般的な意味の偏差値とは少し意味合いが異なる。
1. 私について
ここからが本記事のメインです。(そうだよね?)
1-(1). 基礎学力
一応、この手の記事では成績の経時推移を示しておくのがしきたりみたいなので・・・
昔からすべてを暗記だけで乗り切ってきました。数学は暗記教科。英語も英単語テストだけはどんとこい。国語も古典文法だけなら…()、理科社会は割と真の意味で暗記教科だからだ〜い好き、みたいな。*6実際前の章で数学とか抽象概念の理解に狩られてましたし・・・。
とはいえ、超人的な暗記能力を持っているわけではありません。人より勉強そのものが好きだったのと人よりちょっとだけ粘り強かったことありきの記憶力だと思います。
大学では学年の試験対策委員を務め、日頃から過去問の解答作成や授業まとめ共有を割とワンマンでこなしていたので、CBTの勉強に本腰を入れる前の時点での成績は、、、学年最上位層でした。(この記事にドラマティックな大逆転劇はありません。なんかごめんなさい。最上位層が95%↑やIRT800↑を目指してみた結果のひとつのモデルケースとしてご覧ください。)
1-(2). CBT成績表と試験当日の状況
私のCBT成績表はこちらになります。

所感としては、正直舐めてたところ足元を掬われてしまった感じです。これからは謙虚に生きていきたいところです。
五肢は「こんなん知ら〜〜ん!」みたいな問題が全体で数題、自信がなかったやつは各ブロックに5題ずつくらいありました。
多選択肢はちょっと悩んだ問題もありましたが全問正解、連問は(1)は全部当てて(2)で1問だけ落としました。
試験5日後時点で320問中10問くらいの間違いに気づいていました。蓋を開けてみると320問中20問くらい間違えていて、等化前問題が除外されて結局248問中15問ミスになっていたようですね。
見直しで見つけて修正できたアホなミスが3つくらいあったので、数問の誤答数を争う層にとっては見直しってダイジだと思います。マジで。うっかりミスがどれほど重大なミスとなるかは後述します。
1-(3). 勉強計画と実際
前の記事でも書きましたが、3年の冬に全範囲一周した段階で受けたmm社の模試で82%で、それ以降は4年生の12月にOSCEが終わるまでは大学の試験や課題をこなす以外に特別な勉強はしてきませんでした。4年の11月1日に経過観察のつもりで受験してみたT社の模試は87%くらいでした。
OSCEが終わった次の日から、現状確認や×問題の絞り込み、苦手分野の把握などのために足掛け3日でQBを1周まわし、その後はいったん問題演習から離れて1月の頭までで購入していたすべての講義動画を2~3倍速で一周視聴しました。
前回の記事ではここまで書いて、「ゆ~~~て順風満帆やから、2月頭の本番まで演習と復習のサイクルをこの調子で回し続けとくわw」という感じで締めていました。確か、T社の問題集が積ん読されてて冷えてるといったところで飽きて、アニメ紹介botになっていましたね。今見たらプリプリ紹介してなくてワロタね。
その後、ちゃんとT社の問題集に全部目を通しました。4,000問近くあって10日くらいかかったので、目を通して間違えた問題をピックアップした時点で本番まで1週間を切っていました。残る一週間はひたすら復習です。
そういえば、本番10日前の土日に今年度のmm社の模試を受験しました。
92%で全国18位だったのですが学内では2位でした。魔境?
この成績でもまだ平易な問題でいくつか間違えていたし、特定の分野(法医学)が苦手なまま残っていたことに気がつけたので、教育的ではあったと思います。また、本番よりも難しく設計されている(本番は、概ね78%の得点率になるように均質化される。)ので、高地トレーニングにもなるんかな、知らんけど。まあ、この難易度なので、直前期に受けて爆死してメンタルさよならになるリスクもあると思います。多分10日前受験くらいがベストかと
2. CBTで上を目指すことについて
2-(1). 目的
前述のとおり、CBTは、受験者の「CBTで得点する能力」の推定に長けたテストでありますが、その本来の実施の趣旨は、基準に満たない学生の足切りにあります。
実際、厚労省や大学の学務課や医学教育係以外の立場、すなわち、学生や、病院の研修医採用担当係などにおいてはCBTの目的が誤解されているようにも感じます。アレは本来スコアを競い合うものではなくボーダーを超えたか超えないか、足切りに遭うか遭わないかに注目したテストなんですよね。たぶん
しかし一方で、共用試験の「客観的難易度を均一化する」という束縛条件によって、試験の実施趣旨とは異なりますが個人の能力を幅広く推定できるテストにもなっています。
つまり何が言いたいかというと、CBTで学力バトルしたりその結果を病院の採用基準の一にしたりするのは本来厚労省に意図された目的とはズレているのにもかかわらず、なまじ個人の能力*7を推定する指標としては適切であるので、病院の採用基準とすることも不合理なことではなく、CBTで良い成績をとるということが無意味な行為であると一蹴することはできないのではないか(早口)ということです。
まあ私の大学で聞くところによると関東の病院で研修したい場合はCBTで良い成績を取っておくといいらしいですし、さっき調べたら県内にもCBTの成績表の写しを提出させる病院がありました。*8
将来のために頑張ることは正当化されそうなので、よかったらちゃんと頑張ってる人に対する僻みとかはよしといてね。
ちなみに私は、就職とかは関係なくただ単純にマウント合戦で優位に立つために本気で勉強しました。って言ったら、笑うか___?
2-(2). 手段
勉強法とかのセクションです。
***
↓私が本番10日前くらいに購入したnote記事です。有料ですが、直前期の勉強方針の参考になりましたし、実際本番でもその対策が功を奏してくれました。(知らん人の有料記事をタダで宣伝するこの行為はマジで何?)
note.com
***
2-(2)-i. 全員がやっている勉強法
前述のとおり、IRT方式のテストにおいて問題が流出しているということは本来あってはならないことなのですが、残念ながら高い成績や合格点をとるために必要な1つ目のステップは、市販の問題集による系統的な問題演習に尽きます。アレよくまとまっているので本当に効率が良いんですよね。これについてはあらゆる勉強法記事に同じことが書かれています。
私は、mm社の出版している問題集に加え、T社の出版している問題集もすべて揃えてプール問題にメタっていました。
T社の出してる書籍版問題集は「こあかり」という名前で、大きな本屋やT社HPから買えます。うちの大学の蔵書を調べたら、医学教育学教室の図書室にしかありませんでした(そこにあっていいんだ)
また、予備校の講義を受講する人も多いと思います。前の記事に書きましたが、復習用一元化ツールとして予備校テキストはお手軽なので、そのようにうまく付き合っていけばいいのではないでしょうか。一周見てあとは復習しまくっただけなのであんまり多くは語れないです。
2-(2)-ii. 90%狙いの人の勉強法
予備校について少し触れましたが、正直、市販の問題集だけで合格できると思います。その上で、9割など上位を目指す人は分厚い教科書を読まないといけないのかなどと考えるかもしれませんが、ぶっちゃけ不要だと思います。90%狙いに出張ってくる教科書といえばレビューブックや病気がみえるだと思います。私は予備校テキストと問題集以外あんまりつかっていませんが。
多くのCBT記事が語っているように、市販の問題集を「ちゃんと」ある程度覚えきることができたら90%は意外ととれる・・・と思います。上で述べたように、おそらく出題される項目の多くが平易なものなので。
私が得点率90%付近の実力だったときにやってた特別なことは、予備校テキストで無限に復習する傍ら、mm社の出版している過去のvol.5を図書館で借りて、模擬試験として解いていたことでしょうか。間違えた問題だけメモに書き残して、本番もそのメモを最後の確認用に使用しました。メモによると良いときは94%くらい取れていたようです。これが最後の仕上げになった感があります。
ところで、急に話を飛ばしますが、困難度が正規分布に従うと仮定した場合に、すべての項目のうち10%を間違えたときのθを推定してみました。なんとなく、誤答した項目の困難度によってθも変わりそうな気がしますが、実際どうなのでしょうか。
上から24項目間違えた場合

下から24項目間違えた場合

バランスよく24項目間違えた場合
??????
私の予想と反し、全体の1割を誤答したとき、間違えた項目の困難度の分布は能力値(θ)の劇的な差としては現れませんでした。サンプル3(実質2)じゃなんともいえないかもしれませんが、面倒なので勘弁してくだしあ
むしろ、間違えた項目の個数が、θに大きな影響を与えていることが示唆されました。
上から21項目間違えた場合

下から21項目間違えた場合→θ=2.4
バランスよく21項目間違えた場合

項目数が多いことや、困難度にきれいな分布を仮定している、そもそも私の設定したパラメタが実際とはかけ離れているなどの様々な要因によって真実とは異なる結果を得ているのかもしれませんが、共用試験CBTのIRT稼ぎと正答率のパーセンテージ稼ぎはほぼ同列に語っても良い(厳密性は保証しませんが)という結果が得られました。というかこれについては、共用試験ガイドブックにもあらかじめこのように断ってありました。「正答率とIRTとの間の相関係数はおよそ0.97である」と。すなわち、ぶっちゃけ難問だろうが易問だろうがあんまり関係ないということです。マジでこれまで長々とIRTについて語ってきたのはなんだったんだろう。
したがって、正答率90%以上や、高いIRT標準スコアを狙うのであれば、次に挙げることをバランスよくこなす必要があります。
①困難度が低い項目の迂闊な失点を減らす
②困難度が高い項目の力及ばずの失点を減らす
(こんなん当たり前なんだよなあ・・・)
このうち、比較的簡単に実践できるのは①のほうで、②を詰めていく作業は本当に終わりのない迷路のようなものです。90%を確実に・・・!という方は、①で頑張ることを目標にするのも具体的でいいのかもしれません。
2-(2)-iii. 95%↑やIRT800を目指すための勉強法
超最上位層の人って、市販の問題集をはじめから大体解ける、あるいは1~2周もすればほとんど全問正解できるようになるくらいの人もいると思います(盛ってるように見えるかもしれませんが実際そういう人もいる)。あるいは、最上位層の人ではなくとも、市販の問題集を十分に周回して、もうその問題集の内容は十分に理解と暗記ができたという時期が来ます。そういう人たちって次に何を勉強すればいいかわからなくなるんですよね。わかりきった問題集をさらに5周も10周もやる?ナンセンスですよね。
「そういう層」をターゲットにした解説記事とか体験談って前述したnoteの記事くらいしかないし。
ってかこの記事も偉そうにしてるけど「そういう層」の人からは見下される対象なのかもしれない・・・。そもそも発見されないかもしれない・・・。
一応、私が+αのつもりで特別にやったこと、IRTについて知った今思えばやっておけば良かったことについて述べていきます。私自身は95%↑もIRT800も達成できていないので、ここのセクションでは偉そうなことを言うつもりもありませんし言う資格もありません。ここから先の記載内容は、その効果を証明できる実績がないので、そのつもりで。
私は、IRTを稼ぐためには困難度が高い項目が重要であると考えていました。(ふたを開けてみると、この言説は半分正解半分不正解でしたね。)そこで、T社の出してる書籍問題集の「こあかり パーフェクト」に手を出しました。この問題集は、2010年代前半に出題された項目のうち難問を集めたという趣旨の本です。確かに、自分の知識の穴をつついてくる問題がたくさん載っていましたが、本番その知識が役に立ったかというと微妙なところでした。しかし、「本番出くわす意味わからん問題」というやつらから感じる雰囲気は、今思えば「こあかり パーフェクト」に載ってた難問を解いてるときに感じたそれと近かったように思えます。
したがって、「これくらい細かい知識も聞かれるんや!」という気づきを得るために有用な書籍であると考察します。この気づきを試験1〜2ヶ月前に得ていれば、もっと細かめの知識へのケアが効いてもうちょっとスコアが伸ばせてたかもしれません。
難問といえば、ごくごく稀に、市販の問題集やQAやm4のテキスト、はてはレビューブック、病気がみえるにも載ってないようなどマイナー知識が問われることがあるらしいです。が、私には出題されなかったし、あっても1人につき1~2問くらいだと思われます。ここからも、満点は難しくてもそれに限りなく近づくことは不可能ではないということが示唆されますね・・・。おそろしや
ちなみに、予備校テキストでCBT範囲外になってる疾患の中にも、90%以上狙いのためにはしっかりと押さえておかなくてはならない疾患がたまに含まれていることがあります。予備校メインの方はそこにはご注意を。
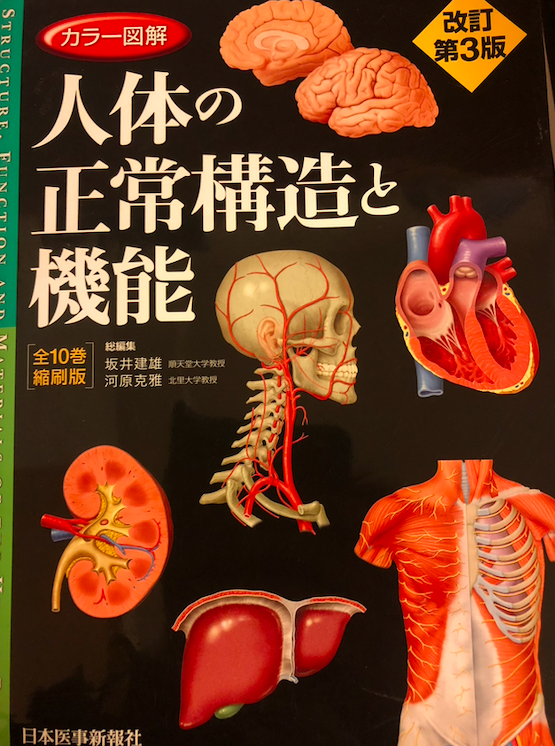
基礎医学をよくまとめた教科書として、「人体の正常構造と機能」という本があります。この本、臓器別に解剖、生理、組織、発生がまとめてあり、消化管や肝胆膵の章では生化学が、血液の章では免疫学がまとめてあって、薬理や微生物以外の基礎医学的知識が一冊に見やすくまとめられています。基礎医学の教科書を一冊だけおすすめしろと言われたらこれを薦めます。
書籍といえば、こあかりにも新問を集めた本があったのをこの記事を書いてるときに知りました。結果的にmm社のvol5が3冊分で手いっぱいだったので知らなくてもよかったのですが、もし本試験前にそのことを知っていたら取り寄せていたと思います。
友人の中にはAnkiを使いこなしている人がいました。私はなんとなく設定とかがめんどくさそうだったので使っていなかったのですが、そこで差がついた可能性もありますね。
***
パラパラと、私がやってきた/やらなかった勉強内容を記しました。別にこれをやっとけみたいなことは言えません。最上位狙いの人は、上に挙げた戦略②をどういう方法で達成するのか自分で考えてみるといいかもしれません(自分ができてないものなので、具体例だけ出して丸投げしておきます)。これまでが優秀で通ってきた方でも、思ってる以上の本気を出さないと私みたく足元を掬われてしまうと思うので、心して臨むのがよろしいかと(結局えらそうじゃん)。
2-(2)-iv. 試験本番の過ごし方
試験当日はVDT作業になることを見越してコンタクトレンズではなくブルーライトカット眼鏡で臨みました。実際のところ、休憩時間が長くとれたので眼への負担は身構えていたよりは少なかったように感じます。この点については杞憂でした。
休憩時間は知識自慢大会になるかもしれません。というか、実際そういう空気でした。同級生の皆さんにはご迷惑おかけしました。
こういう空気は耳栓つけて回避して自分の勉強に集中しとけって記事も多いですし、知識自慢大会が嫌いな人も多いことは知っていますが、もし参加できるのなら参加するのも一つの手だと思います。参加しないのも一つの手です。そういえばうちの大学では耳栓NGでした。
私は普段から1人で勉強するタイプ*9だったので、他人の勉強内容を知る機会がそこしかありませんでした。1人で勉強していると知りようもないのですが、私以外のみなさんも非常に勉強していらっしゃいました。話してみるだけで思いがけない知識を仕入れることができると思います。当日の自慢大会は私自身の得点UPにはつながらなかったのですが、試験後に聞くと私の知識は数問分だけ友人の得点UPにつながっていたらしいです。
※答え合わせは、始まりそうになる度に「止めようね!」と声を荒げていました。知識自慢はやっていいけど答え合わせはやらないほうがいいです。
3. まとめ
ぶっちゃけ共用試験CBTではIRTなんて無視して正答率でことを語ってもおそらくおkです。難問も易問もほぼ同じ(1/248)点なので、基本的にはまず簡単なところを固めて難しい問題は二の次でいきましょう。
2〜3ヶ月、憂鬱な気分にならない程度(←重要)の期間集中すれば、きっと大丈夫だと思います。1年間勉強したってのはさすがに恐怖心煽り過ぎな気がします。
5. 参考
共用試験ガイドブック第18版(令和2年)(公益財団法人 医療系大学間共用試験実施評価機構(CATO))
「新テスト」の学力測定方法を知るIRT入門(河合出版)
Rによる項目反応理論(オーム社)
項目反応理論[入門編]【第2版】(朝倉書店)
研究委員会企画チュートリアルセミナー
項目反応理論(IRT)の考え方と実践 ―測定の質の高いテストや尺度を作成するための技術―
http://satoshiusami.com/%E6%95%99%E8%82%B2%E5%BF%83%E7%90%86%E5%AD%A6%E4%BC%9A%E3%83%81%E3%83%A5%E3%83%BC%E3%83%88%E3%83%AA%E3%82%A2%E3%83%AB2018%E8%B3%87%E6%96%99.pdf
*1:で、あるとすれば、こんなものの成績を競い合うなんてナンセンスですよね。この点については後述
*2:というか、仮免筆記試験もそれなりに範囲広いと思うのになんであんなにみんな合格るんだろう
*3:「○○しながら〜△△点」とかはまああからさまだけど(もう逆に許してやったら?)、「成績△△だったけど○にてえ」(婉曲パターン)とか、「や、僕はUSMLEの勉強してるから眼中にネんだわ」(負け惜しみパターン)、「勉強やってるみんなが怖い、もっと遊べよ」(所謂逆マウント、あるいは一周回って自分の要領を鼻にかけてる)、「言動があんま好きじゃない人が高得点を取った事象そのもの」(マウントが発生する原因、だいたい全部これだろ)とかもすご〜く広い意味のマウントになるみたいです。私調べ
*4:学校行ってない人は……臼。
*5:ん、4連問は?後述します。
*7:ただし、CBTで得点する能力(学力・記憶力・粘っこさなど)しか測れないので、臨床手技の巧さやコミュ力など、総合的な能力判断の一材料としてしか用いられません。
*8:紙切れ1枚捨てただけで出願不可能になる病院怖い。
*9:友達が少なかったとも言えるだろうし、それだけじゃなくてなんとなくマウンティングされそうで近寄り難いタイプなんだと思われてそう